V2 Supplementary Samples for
AISHELL-3:
A Multi-Speaker Mandarin TTS Corpus
OpenSLR: www.openslr.org/93/ Dataset Download: www.aishelltech.com/aishell_3 Link to v1 version: sos1sos2Sixteen.github.io/aishell3 For further questions regarding the dataset: tech@aishelldata.com
Authors
- SHI, Yao (Wuhan University, Duke-Kunshan University)
- BU, Hui (AISHELL)
- XU, Xin (AISHELL)
- ZHANG, Shaoji (AISHELL)
- LI, Ming (Duke-Kunshan University, Wuhan University) ······ ming.li369@dukekunshan.edu
Abstract
In this paper, we present AISHELL-3, a large-scale multi-speaker Mandarin speech corpus which could be used to train multi-speaker Text-To-Speech (TTS) systems. The corpus contains roughly 85 hours of emotion-neutral recordings spanning across 218 native Chinese mandarin speakers. Their auxiliary attributes such as gender, age group and native accents are explicitly marked and provided in the corpus. Moreover, transcripts in Chinese character-level and pinyin-level are provided along with the recordings. We also present some data processing strategies and techniques which match with the characteristics of the presented corpus and conduct experiments on multiple speech-synthesis systems to assess the quality of the generated speech samples, showing promising results. The corpus is available online at openslr.org/93/ under Apache v2.0 license.
Dataset Samples
Sample audios and labels from the AISHELL-3 dataset (in original 44.1kHz format)
zai4 jiao4 xue2 lou2 nei4 shi4 fang4 da4 liang4 yan1 wu4
ti4 wo3 bo1 fang4 xiang1 si1 feng1 yu3 zong1
Synthesis Samples
The following section exhibits audio samples generated by Tacotron trained on AISHELL-3.
Cross-Speaker Migration Duration on Fastspeech
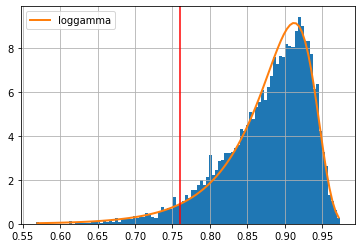
Determining the mutual-exclusive threshold d
When counting the number of distinct voices from a pool of sampled voiced U, we define two voices are mutually-exlusive if their respective mean embedding in the SV embedding space share a cosine-similarity of less than d. (see Section. 4.5 of the paper) This threshold d is chosen to be the 5% quantile (ppf(0.05)) of the fitted distribution of the distance between known sample points and their respective class-mean. We first gather data for this analysis by calculating the similairty between all ground-truth samples and their speaker mean embeddings. The distribution of the collected data are fitted using the python package `Fitter`, which tries to fit the given dataset using common distributions and report the top-k best choices. The best fitted distribution we chose is the loggmma distribution .